Introduction The Elastic Stack
The Elastic Stack, formerly known as the ELK Stack, is a powerful suite of open-source tools designed for data ingestion, storage, analysis, and visualization. Comprising Elasticsearch, Logstash, and Kibana, the Elastic Stack offers a comprehensive solution for managing diverse datasets and extracting actionable insights from them. Whether handling log data, metrics, or any other type of structured or unstructured information, the Elastic Stack provides a flexible and scalable platform to meet the demands of modern data-driven applications and businesses. In this guide, we’ll explore the installation and setup of Elasticsearch, Logstash, and Kibana on Ubuntu 20.04, enabling you to leverage the full capabilities of the Elastic Stack for your data analytics needs.

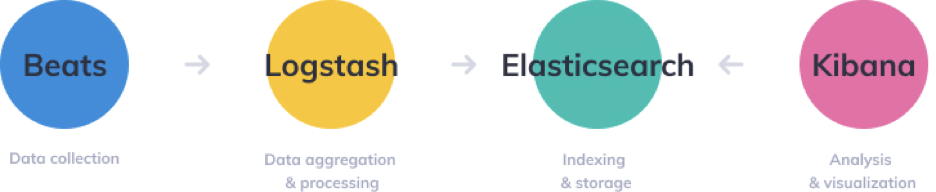
The Elastic Stack has four main components:
- Elasticsearch: a distributed RESTful search engine which stores all of the collected data.
- Logstash: the data processing component of the Elastic Stack which sends incoming data to Elasticsearch.
- Kibana: a web interface for searching and visualizing logs.
- Beats: lightweight, single-purpose data shippers that can send data from hundreds or thousands of machines to either Logstash or Elasticsearch.
In this tutorial, you will install the Elastic Stack on an Ubuntu 20.04 server. You will learn how to install all of the components of the Elastic Stack — including Filebeat, a Beat used for forwarding and centralizing logs and files — and configure them to gather and visualize system logs. Additionally, because Kibana is normally only available on the localhost, we will use Nginx to proxy it so it will be accessible over a web browser. We will install all of these components on a single server, which we will refer to as our Elastic Stack server.
Prerequisites
To complete this tutorial, you will need the following:
- An Ubuntu 20.04 server with 4GB RAM and 2 CPUs set up with a non-root sudo user. You can achieve this by following the Initial Server Setup with Ubuntu 20.04.For this tutorial, we will work with the minimum amount of CPU and RAM required to run Elasticsearch. Note that the amount of CPU, RAM, and storage that your Elasticsearch server will require depends on the volume of logs that you expect.
- OpenJDK 11 installed
- Nginx installed on your server, which we will configure later in this guide as a reverse proxy for Kibana. Follow our guide on How to Install Nginx on Ubuntu 20.04 to set this up.
Installing and Configuring Elasticsearch
Update Package Index:
Before installing Elasticsearch, update the package index on your Ubuntu system by running:
sudo apt updateInstall Java:
Elasticsearch requires Java to be installed. Install the default JDK package using:
sudo apt install default-jdkAdd Elasticsearch Repository:
Fetch the Elasticsearch GPG key and add the repository to your system:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
sudo sh -c 'echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" > /etc/apt/sources.list.d/elastic-7.x.list'Install Elasticsearch:
Update the package index again, then install Elasticsearch:
sudo apt update
sudo apt install elasticsearchStart and Enable Elasticsearch Service:
Start the Elasticsearch service and enable it to start on system boot:
sudo systemctl start elasticsearch
sudo systemctl enable elasticsearchConfigure Elasticsearch:
Edit the Elasticsearch configuration file to allow connections from external devices:
sudo nano /etc/elasticsearch/elasticsearch.ymlSet network.host to 0.0.0.0 to allow connections from any IP address. Save the file and exit.
Restart Elasticsearch:
Restart the Elasticsearch service to apply the configuration changes:
sudo systemctl restart elasticsearchVerify Elasticsearch Installation:
You can verify that Elasticsearch is running properly by accessing it through your web browser or using curl:
curl -X GET "localhost:9200/"Output
Output
{
"name" : "Elasticsearch",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "qqhFHPigQ9e2lk-a7AvLNQ",
"version" : {
"number" : "7.7.1",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}Access Elasticsearch from Remote Hosts
If you intend to access Elasticsearch from remote hosts, ensure that your firewall rules allow traffic on port 9200, or modify Elasticsearch configuration to bind to a specific IP address.
Installing and Configuring the Kibana Dashboard:
Install Kibana:
Start by updating the package index and installing Kibana using the following commands:
sudo apt update
sudo apt install kibanaStart and Enable Kibana Service:
Once installed, start the Kibana service and enable it to start on system boot:
sudo systemctl start kibana
sudo systemctl enable kibanaConfigure Kibana:
Edit the Kibana configuration file to set up necessary parameters. Open the configuration file in a text editor:
sudo nano /etc/kibana/kibana.ymlEnsure the following settings are configured appropriately:
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://localhost:9200"]These settings allow Kibana to listen on all network interfaces and connect to Elasticsearch on the local machine. Save the file and exit the editor.
Restart Kibana:
After making changes, restart the Kibana service to apply the configuration:
sudo systemctl restart kibanaBecause Kibana is configured to only listen on localhost, we must set up a reverse proxy to allow external access to it. We will use Nginx for this purpose, which should already be installed on your server.
First, use the openssl command to create an administrative Kibana user which you’ll use to access the Kibana web interface. As an example we will name this account kibanaadmin, but to ensure greater security we recommend that you choose a non-standard name for your user that would be difficult to guess.
The following command will create the administrative Kibana user and password, and store them in the htpasswd.users file. You will configure Nginx to require this username and password and read this file momentarily:
echo "kibanaadmin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.usersEnter and confirm a password at the prompt. Remember or take note of this login, as you will need it to access the Kibana web interface.
Next, we will create an Nginx server block file. As an example, we will refer to this file as your_domain, although you may find it helpful to give yours a more descriptive name. For instance, if you have a FQDN and DNS records set up for this server, you could name this file after your FQDN.
Using nano or your preferred text editor, create the Nginx server block file:
sudo nano /etc/nginx/sites-available/your_domainAdd the following code block into the file, being sure to update your_domain to match your server’s FQDN or public IP address. This code configures Nginx to direct your server’s HTTP traffic to the Kibana application, which is listening on localhost:5601. Additionally, it configures Nginx to read the htpasswd.users file and require basic authentication.
Note that if you followed the prerequisite Nginx tutorial through to the end, you may have already created this file and populated it with some content. In that case, delete all the existing content in the file before adding the following:
server {
listen 80;
server_name your_domain;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}When you’re finished, save and close the file.
Next, enable the new configuration by creating a symbolic link to the sites-enabled directory. If you already created a server block file with the same name in the Nginx prerequisite, you do not need to run this command:
sudo ln -s /etc/nginx/sites-available/your_domain /etc/nginx/sites-enabled/your_domainThen check the configuration for syntax errors:
sudo nginx -tIf any errors are reported in your output, go back and double check that the content you placed in your configuration file was added correctly. Once you see syntax is ok in the output, go ahead and restart the Nginx service:
sudo systemctl reload nginxIf you followed the initial server setup guide, you should have a UFW firewall enabled. To allow connections to Nginx, we can adjust the rules by typing:
sudo ufw allow 'Nginx Full'Kibana is now accessible via your FQDN or the public IP address of your Elastic Stack server. You can check the Kibana server’s status page by navigating to the following address and entering your login credentials when prompted:
Access Kibana Dashboard:
Open a web browser and navigate to http://localhost:5601 or http://your_server_ip:5601 if accessing remotely. You should see the Kibana login page.
Log in to Kibana:
Log in to Kibana using the default credentials (username: elastic, password: changeme). It’s recommended to change the default password immediately after logging in for security purposes.
Explore Kibana Dashboard
Once logged in, you can explore the Kibana dashboard, create visualizations, build dashboards, and perform data analysis tasks. Kibana provides a user-friendly interface for interacting with Elasticsearch data.
Secure Kibana (Optional):
For production environments, it’s crucial to secure Kibana by setting up authentication, configuring SSL/TLS encryption, and implementing other security measures as per your organization’s requirements.
Installing and Configuring Logstash
Although it’s possible for Beats to send data directly to the Elasticsearch database, it is common to use Logstash to process the data. This will allow you more flexibility to collect data from different sources, transform it into a common format, and export it to another database.
Install Logstash with this command:
sudo apt update
sudo apt install logstashAfter installing Logstash, you can move on to configuring it. Logstash’s configuration files reside in the /etc/logstash/conf.d directory. For more information on the configuration syntax, you can check out the configuration reference that Elastic provides. As you configure the file, it’s helpful to think of Logstash as a pipeline which takes in data at one end, processes it in one way or another, and sends it out to its destination (in this case, the destination being Elasticsearch). A Logstash pipeline has two required elements, input and output, and one optional element, filter. The input plugins consume data from a source, the filter plugins process the data, and the output plugins write the data to a destination.
Start and Enable Logstash Service:
Once installed, start the Logstash service and enable it to start on system boot:
sudo systemctl start logstash
sudo systemctl enable logstashConfigure Logstash Pipelines:
Logstash configuration involves defining pipelines that specify input sources, filters for data transformation, and output destinations. Configuration files are located in /etc/logstash/conf.d/. Create a new configuration file for your Logstash pipeline:
sudo nano /etc/logstash/conf.d/my_pipeline.confCreate a configuration file called 02-beats-input.conf where you will set up your Filebeat input:
sudo nano /etc/logstash/conf.d/02-beats-input.confInsert the following input configuration. This specifies a beats input that will listen on TCP port 5044.
input {
beats {
port => 5044
}
}Example Configuration:
Here’s a basic example configuration file to get you started:
input {
# Specify your input source (e.g., file, beats, syslog)
}
filter {
# Apply filters for data transformation (e.g., grok, date, mutate)
}
output {
# Define output destination (e.g., Elasticsearch, stdout)
}Restart Logstash:
After configuring the Logstash pipeline, restart the Logstash service to apply the changes:
sudo systemctl restart logstashVerify Logstash Configuration:
Check Logstash logs for any errors or warnings:
Check Logstash logs for any errors or warnings:Test Logstash Pipeline:
Once Logstash is running without errors, test your Logstash pipeline by sending sample data through the configured input source and verifying that it’s processed and sent to the output destination as expected.
Advanced Configuration:
Logstash offers a wide range of input, filter, and output plugins to customize data processing according to your requirements. Refer to the official Logstash documentation for detailed configuration options and plugin usage.
By following these steps, you have successfully installed and configured Logstash on your Ubuntu 20.04 system. You can now use Logstash to ingest, transform, and ship data from various sources to your desired destinations, such as Elasticsearch for indexing and analysis.